

Database maintenance
Database maintenance
EventStoreDB requires regular maintenance with two operational concerns:
- Scavenging for freeing up space after deleting events
- Backup and restore for disaster recovery
You might also be interested learning about EventStoreDB diagnostics and indexes, which might require some Ops attention.
Scavenging events
When you delete events or streams in EventStoreDB, they aren't removed immediately. To permanently delete these events you need to run a 'scavenge' on your database.
A scavenge reclaims disk space by rewriting your database chunks, minus the events to delete, and then deleting the old chunks. Scavenges only affect completed chunks, so deleted events in the current chunk are still there after you run a scavenge.
After processing the chunks, the operation updates the chunk indexes using a merge sort algorithm, skipping events whose data is no longer available.
Warning
Once a scavenge has run, you cannot recover any deleted events.
Index scavenge
Before version 4.0.2, a scavenge operation only worked with database chunk files. Since version 4.0.2 that reordering also happens inside the index files.
Active chunk
The active (last) chunk won't be affected by the scavenge operation as scavenging requires creating a new empty chunk file and copy all the relevant events to it. As the last chunk is the one were events are being actively written, scavenging of the currently active chunk is not possible. It also means that all the events from truncated and deleted streams won't be removed from the current chunk.
Starting a scavenge
Scavenges are not run automatically by EventStoreDB. We recommend that you set up a scheduled task, for example using cron or Windows Scheduler, to trigger a scavenge as often as you need.
You start a scavenge by issuing an empty POST request to the HTTP API with the credentials of an admin or ops user:
curl -i -d {} -X POST http://localhost:2113/admin/scavenge -u "admin:changeit"Tips
Scavenge operations have other options you can set to improve performance. For example, you can set the number of threads to use. Check the API docs for more details.
HTTP/1.1 200 OK
Access-Control-Allow-Methods: POST, OPTIONS
Access-Control-Allow-Headers: Content-Type, X-Requested-With, X-Forwarded-Host, X-Forwarded-Prefix, X-PINGOTHER, Authorization, ES-LongPoll, ES-ExpectedVersion, ES-EventId, ES-EventType, ES-RequiresMaster, ES-HardDelete, ES-ResolveLinkTos
Access-Control-Allow-Origin: *
Access-Control-Expose-Headers: Location, ES-Position, ES-CurrentVersion
Content-Type:
Server: Mono-HTTPAPI/1.0
Date: Wed, 19 Sep 2018 10:25:55 GMT
Content-Length: 0
Keep-Alive: timeout=15,max=100Tips
If you need to restart a stopped scavenge, you can specify the starting chunk ID.
You can also start scavenges from the Admin page of the Admin UI.
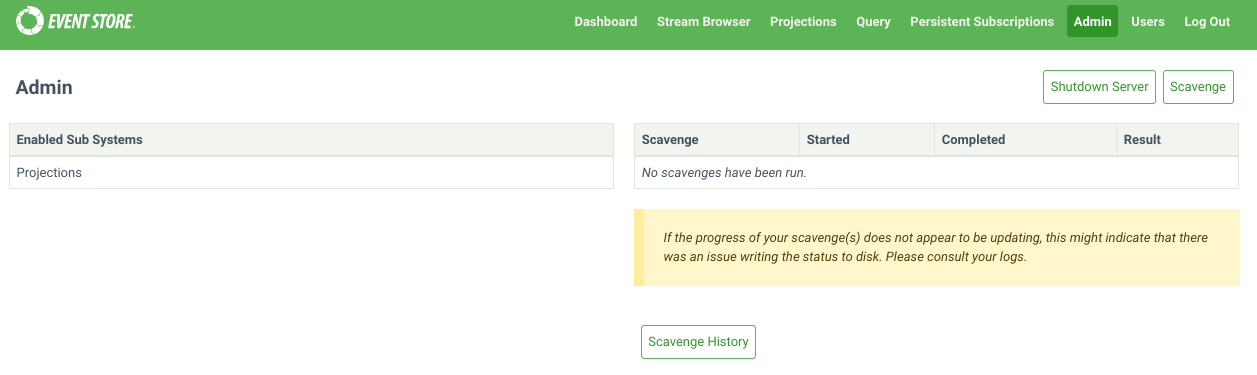
Each node in a cluster has its own independent database. As such, when you run a scavenge, you need to issue a scavenge request to each node.
Stopping a scavenge
Stop a running scavenge operation by issuing a DELETE request to the HTTP API with the credentials of an admin or ops user and the ID of the scavenge you want to stop:
curl -i -X DELETE http://localhost:2113/admin/scavenge/{scavengeId} -u "admin:changeit"You can also stop scavenges from the Admin page of the Admin UI.
Tips
Each node in a cluster has its own independent database. As such, when you run a scavenge, you need to issue a scavenge request to each node.
Scavenge progress
As all other things in EventStoreDB, the scavenge process emit events that contain the history of scavenging. Each scavenge operation will generate a new stream and the stream will contain events related to that operation.
Refer to the $scavenges stream documentation to learn how you can use it to observe the scavenging operation progress and status.
How often to scavenge
This depends on the following:
- How often you delete streams.
- How you set
$maxAge,$maxCountor$tbmetadata on your streams. - Have you enabled writing stat events to the database.
You should scavenge more often if you expect a lot of deleted events. For example, if you enable writing stats events to the database, you will get them expiring after 24 hours. Since there are potentially thousands of those events generated per day, you have to scavenge at least once a week.
Scavenging online
It's safe to run a scavenge while EventStoreDB is running and processing events, as it's designed to be an online operation.
Warning
Scavenging increases the number of reads/writes made to disk, and it is not recommended when your system is under heavy load.
Scavenging options
Below you can find some options that change the way how scavenging works on the server node.
Disable scavenge merging
EventStoreDB might decide to merge indexes, depending on the server settings. The index merge is IO intensive operation, as well as scavenging, so you might not want them to run at the same time. Also, the scavenge operation rearranges chunks, so indexes might change too. You can instruct EventStoreDB not to merge indexes when the scavenging is running.
| Format | Syntax |
|---|---|
| Command line | --disable-scavenge-merging |
| YAML | DisableScavengeMerging |
| Environment variable | EVENTSTORE_DISABLE_SCAVENGE_MERGING |
Default: false, so EventStoreDB might run the index merge and scavenge at the same time.
Scavenge history
Each scavenge operation gets an id and creates a stream. You might want to look at these streams to see the scavenge history, see how much time each operation took and how much disk space was reclaimed. However, you might not want to keep this history forever. Use the following option to limit how long the scavenge history stays in the database:
| Format | Syntax |
|---|---|
| Command line | --scavenge-history-max-age |
| YAML | ScavengeHistoryMaxAge |
| Environment variable | EVENTSTORE_SCAVENGE_HISTORY_MAX_AGE |
Default: 30 (days)
Always keep scavenged
Scavenging aims to save disk space. Therefore, if the scavenging process finds out that the new chunk is for some reason larger or has the same size as the old chunk, it won't replace the old chunk because there's no disk space to save.
Such behaviour, however, is not always desirable. For example, you might want to be sure that events from deleted streams are removed from the disk. It is especially relevant in the context of personal data deletion.
When the AlwaysKeepScavenged option is set to true, EventStoreDB would replace the old chunk with the new one unconditionally, giving you guarantee that all the deleted events in the scavenged chunk actually disappear.
| Format | Syntax |
|---|---|
| Command line | --always-keep-scavenged |
| YAML | AlwaysKeepScavenged |
| Environment variable | EVENTSTORE_ALWAYS_KEEP_SCAVENGED |
Default: false
EventStoreDB will always keep one event in the stream even if the stream was deleted, to indicate the stream existence and the last event version. That last event in the deleted stream will still be there even with AlwaysKeepScavenged option enabled. Read more about deleting streams to avoid keeping sensitive information in the database, which you otherwise would consider as deleted.
Ignore hard delete
When you delete a stream, you can use either a soft delete or hard delete. When using hard delete, the stream gets closed with a tombstone event. Such an event tells the database that the stream cannot be reopened, so any attempt to append to the hard-deleted stream will fail. The tombstone event doesn't get scavenged.
You can override this behaviour and tell EventStoreDB that you want to delete all the traces of hard-deleted streams too, using the option specified below. After a scavenge operation runs, all hard-deleted streams will be open for writing new events again.
Active chunk
If you hard-delete a stream in the current chunk, it will remain hard-deleted even with this option enabled. It's because the active chunk won't be affected by the scavenge.
| Format | Syntax |
|---|---|
| Command line | --unsafe-ignore-hard-delete |
| YAML | UnsafeIgnoreHardDelete |
| Environment variable | EVENTSTORE_UNSAFE_IGNORE_HARD_DELETE |
Default: false
Unsafe
Setting this option to true disables hard deletes and allows clients to append to deleted streams. For that reason, the option is considered unsafe and should be used with caution.
Database backup and restore
Backing up an EventStoreDB database is straightforward but relies on carrying out the steps below in the correct order.
Types of backups
There are two main ways to perform backups:
Disk snapshots
If your infrastructure is virtualized, disk snapshots is an option and the easiest to perform backup and restore operations.
Regular file copy
- Simple full backup: when the DB size is small and the frequency of appends is low.
- Differential backup: when the DB size is large or the system has a high append frequency.
Considerations for backup and restore procedures
Backing up one node is recommended. However, ensure that the node chosen as a target for the backup is:
- up to date
- connected to the cluster.
For additional safety, you can also backup at least a quorum of nodes.
Do not back up a node at the same time as running a scavenge operation.
When either running a backup or restoring, do not mix backup files of different nodes.
The restore must happen on a stopped node.
The restore process can happen on any node of a cluster.
You can restore any number of nodes in a cluster from the same backup source. It means, for example, in the event non-recoverable three nodes cluster, that the same backup source can be used to restore a completely new three nodes cluster.
When you restore a node that was the backup source, perform a full backup after recovery.
Database files information
By default, there are two directories containing data that needs to be included in the backup:
db\where the data is locatedindex\where the indexes are kept.
The exact name and location are dependent on your configuration.
db\contains:- the chunks files, named
chk-X.YwhereXis the chunk number andYthe version. - the checkpoints files,
*.chk(chaser.chk,epoch.chk,proposal.chk,truncate.chk,writer.chk)
- the chunks files, named
index\contains:- the index map:
indexmap - the indexes: UUID named files , e.g
5a1a8395-94ee-40c1-bf93-aa757b5887f8
- the index map:
Scenarios
Disks snapshot
If the db\ and index\ directories are on the same volume, a snapshot of that volume is enough.
However, if they are on different volumes, take first a snapshot of the volume containing the index\ directory and then a snapshot of the volume containing the db\ directory.
Simple full backup & restore
Backing up
- Copy any index checkpoint files (
<index directory>\**\*.chk) to your backup location. - Copy the other index files to your backup location (the rest of
<index directory>, excluding the checkpoints). - Copy the database checkpoint files (
*.chk) to your backup location. - Copy the chunk files (
chunk-X.Y) to your backup location.
For example, with a database in data and index in data/index:
rsync -aIR data/./index/**/*.chk backup
rsync -aI --exclude '*.chk' data/index backup
rsync -aI data/*.chk backup
rsync -a data/*.0* backupRestoring a database
- Ensure the EventStoreDB process is stopped. Restoring a database on running instance is not possible and, in most cases, will lead to data corruption.
- Copy all files to the desired location.
- Create a copy of
chaser.chkand call ittruncate.chk. This effectively overwrites the restoredtruncate.chk.
Differential backup & restore
The following procedure is designed to minimize the backup storage space, and can be used to do a full and differential backup.
Backing up
Backup the index
- If there are no files in the index directory (apart from directories), go to step 7.
- Copy the
index/indexmapfile to the backup. If the source file does not exist, repeat until it does. - Make a list
indexFilesof all theindex/<GUID>andindex/<GUID>.bloomfilterfiles in the source. - Copy the files listed in
indexFilesto the backup, skipping file names already in the backup. - Compare the contents of the
indexmapfile in the source and the backup. If they are different (i.e. the indexmap file has changed since step 2, or no longer exists), go back to step 2. - Remove
index/<GUID>andindex/<GUID>.bloomfilterfiles from the backup that are not listed inindexFiles. - Copy the
index/stream-existence/streamExistenceFilter.chkfile (if present) to the backup. - Copy the
index/stream-existence/streamExistenceFilter.datfile (if present) to the backup.
Backup the log
- Rename the last chunk in the backup to have a
.oldsuffix. e.g. renamechunk-000123.000000tochunk-000123.000000.old - Copy
chaser.chkto the backup. - Copy
epoch.chkto the backup. - Copy
writer.chkto the backup. - Copy
proposal.chkto the backup. - Make a list
chunkFilesof all chunk files (chunk-X.Y) in the source. - Copy the files listed in
chunkFilesto the backup, skipping file names already in the backup. All files should copy successfully - none should have been deleted since scavenge is not running. - Remove any chunks from the backup that are not in the
chunksFileslist. This will include the.oldfile from step 9.
Restoring a database
- Ensure the Event Store DB process is stopped. Restoring a database on running instance is not possible and, in most cases, will lead to data corruption.
- Copy all files to the desired location.
- Create a copy of
chaser.chkand call ittruncate.chk.
Other options
There are other options available for ensuring data recovery, that are not strictly related to backups.
Additional node (aka Hot Backup)
Increase the cluster size from 3 to 5 to keep further copies of data. This increase in the cluster size will slow the cluster's writing performance as two follower nodes will need to confirm each write.
Alternative storage
Set up a durable subscription that writes all events to another storage mechanism such as a key/value or column store. These methods would require a manual set up for restoring a cluster node or group.
Backup cluster
Use a second EventStoreDB cluster as a backup. Such a strategy is known as a primary/secondary back up scheme.
The primary cluster asynchronously pushes data to the second cluster using a durable subscription. The second cluster is available in case of a disaster on the primary cluster.
If you are using this strategy, we recommend you only support manual failover from primary to secondary as automated strategies risk causing a split brain problem.